22/06/2026
Why Human-Verified Primary Research Is Becoming the Control Group for AI Data
When AI writes the brief, sources the panel, and synthesizes the deck, what's left to trust? Why human-verified primary research is becoming the control group every research stack now needs.
A PE deal team I spoke with last month opened a survey deliverable on a Tuesday morning. Sample size looked right. Geographic spread looked right. The open-ends were the problem. Six different "VPs of procurement" used the phrase "streamline our vendor consolidation efforts" inside the same week. Two of them used it twice. When the team asked the vendor how the respondents had been sourced and screened, the answer came back vague: bought through a panel, no record of who had actually qualified each person against the brief. By Wednesday afternoon the file was written off, and the same questions were re-run, this time through a firm that could show its sourcing and put a named researcher behind every interview.
That moment is the thesis of this article. Human-led primary research is no longer one option on a menu. It is becoming the control group: the reference standard against which AI-generated, AI-synthesised, and AI-augmented research has to be measured. If a buyer cannot point to a layer of directly sourced, human-conducted interviews underneath the synthesis, they cannot tell whether the synthesis is reading the market or reading itself.
That argument gets uncomfortable fast for anyone shipping research in 2026. It should.

The data layer is collapsing into itself
The risk most buyers are not yet pricing in is a closed loop. An AI tool drafts the screener. An AI-augmented panel routes that screener to respondents who increasingly use AI assistants to write their open-ends. The dataset is cleaned by an AI scrubber, summarized by an LLM, and dropped into a slide deck the deal team reads at 11pm before IC. Each step is defensible on its own, and each tool earns its place on lower-stakes work. The problem is the compound effect: the buyer ends up reading a polished version of their own assumptions back to themselves.
This is the data integrity problem we wrote about in our piece on survey panel fraud, except the failure mode has migrated up the stack. Panel fraud used to mean fake humans. The new version is real panels feeding through enough AI-touched layers that the original signal cannot be reconstructed. Synthetic respondents are the loud version of the problem. The quiet version is AI-generated text inside a real dataset that nobody flagged, because nobody asked.
Buyers ask us what actually changed in 2026. The honest answer is: volume. Three years ago a deal team could assume an open-end was a sentence a person typed. That assumption no longer holds, and rebuilding it is what this article is about.
What human-verified primary research actually means
Human-verified primary research means a real, qualified person was sourced for the specific project, interviewed by a human researcher in their own language, and the reasoning behind their answers was captured and traceable to a disclosed source. It rests on three components, all of which have to be present.
Directly sourced, screened respondents
The firm sources the respondent for your project and screens them for relevance before and during the interview, rather than buying an anonymous seat from a panel it cannot audit. This matters because most of the verification language in the SERP for this keyword operates at the panel level: "100% verified samples," "identity verification," SOC-attested compliance. Those signals tell you the panel knows who paid the panel. They do not tell you whether the person who answered was the right person for your question. Direct sourcing is a different bar: the firm owns the respondent relationship, controls the screen, and can stand behind the qualification of every interview it delivers. At Bell & Holmes we interview current market players and industry experts, not former employees several years out of the role, and we check qualification both at sourcing and live in the call.
Native-language, human-conducted conversation
The interview is conducted by a human researcher who speaks the respondent's language, and the conversation is written up, typically in English, close to the respondent's own words — close enough to drop a line straight into a slide. Not an AI-moderated chat. Not a machine back-translation that smooths the rough edges out of an answer. A subject-matter interview with a German automotive supplier is conducted in German, by an interviewer who speaks German, and you receive the write-up in English alongside the synthesis. B&H runs primary interviews in 35+ languages across 140+ countries, which is the operational reason we can put a Tokyo respondent and a São Paulo respondent on the same project without routing either through machine translation.
Captured reasoning, with disclosed provenance
The "why" comes through in the write-up, in the respondent's own words, and you can see the company and role of the person who said it. Ratings are easy to generate at scale because the answer space is small. A person's reasoning for a rating is much harder to synthesize convincingly, which is exactly what makes it the verification surface. We disclose the company and position of each interviewee on the deliverable, not their name, so you can judge whether the source is credible for the question without compromising the respondent. When a firm shows you a 1-10 score with no recorded reasoning and no disclosed source behind it, you have a number, not a finding.
Five things people sometimes call human verification, and should not:
- CAPTCHA gating. Proves a human clicked. Says nothing about who they were.
- IP checks. Prove geography. Say nothing about role or expertise.
- Panel-level identity verification. Proves the panel knows who paid the panel. Says nothing about whether the respondent was right for your brief.
- AI-moderated interviews. Prove a conversation happened. Say nothing about who was on the other end or whether their reasoning was captured intact.
- AI participant screening. Proves an algorithm thought the respondent was eligible at the front of the funnel. Says nothing about whether the answer at the back of the funnel was real.
All five are useful for what they do. None is what we mean here.
A note on certifications, because the SERP leans on them. Firm-level governance standards are real signals about how a research operation handles data privacy, methodology, and process controls. They sit one floor above the question this article is asking: they do not tell you whether a specific respondent on a specific project was the right qualified human. A firm can hold every badge in the category and still hand you a finding you cannot trace to a credible disclosed source. The control-group test is downstream of the badge.

How to choose a qualitative market research company in 2026
Choose on whether the firm can produce evidence that survives a control-group test, not on whose methodology page reads best — every firm has a strong one. Four questions separate the vendors that can from the ones that cannot. Ask them in the procurement call; the vendor that answers all four cleanly is the one you want.
- Do you source respondents directly, or buy them from a panel? Direct sourcing means the firm owns the relationship and can stand behind the screen. Panel-bought respondents may be excellent, but they may also have come through layers of resale the firm cannot audit.
- Are your experts current market players, and how do you screen them? Current beats former, and a firm that can describe its screen, at sourcing and during the call, is telling you it controls quality rather than outsourcing it.
- Are interviews conducted by human researchers in the respondent's native language, and does the deliverable capture what the respondent actually said? The evidence is the respondent's reasoning in their own words, written up close to verbatim and attributed to a disclosed company and role. If all you get back is a bare score, or an AI synthesis with no traceable source underneath it, you are buying interpretation, not data.
- What is your stated position on synthetic respondents? Watch for "we use them carefully" answers. Either the firm uses them and discloses it on every project, or it does not, or it has not thought about the question. The third answer is the one to walk away from.
That set disqualifies most of the SERP for this keyword. That is the point. The few firms that pass it are the ones you can put underneath an AI-heavy research stack and trust the result.
Why a control group, not just another input
A control group exists for one reason: to make the test condition interpretable. In an experiment, take it away and the test results still look like numbers, but you cannot tell what they mean. The same logic now applies to the research stack.
When syndicated data, third-party benchmarks, AI-augmented panels, and synthesis tools all agree on a number, the temptation is to treat the agreement as confirmation. It is not. Confirmation requires an independent reference. Without one, agreement may just mean the sources share a common upstream input, and that input might be wrong.
The headline trust signals in this category make the problem harder, not easier. The marketing language the category now leans on — billion-plus-reach professional graphs, coverage across hundreds of industries, "100% verified samples" — describes scale. It is silent on whether the specific respondents behind your specific finding were independently sourced and screened for your question, or whether they came through the same upstream pipes as everyone else's. Scale tells you what a vendor has built. Independence tells you whether you can trust what it produces.
The proprietary data-quality protocols some firms now sell as a branded virtue do not close this gap either. Suspicious-pattern detection, human reviewers, automated fraud flags: these are real improvements over the panels they replace, but they are vendor-internal controls. They tell you the firm has a process for keeping its own data clean. A control group is something different: an independent layer the buyer can check the rest of the stack against. The two are complements, not substitutes.
The four approaches now on the market do not compete on the same axis, which is the point. The table below is the version of that comparison we use in scoping calls with deal teams.
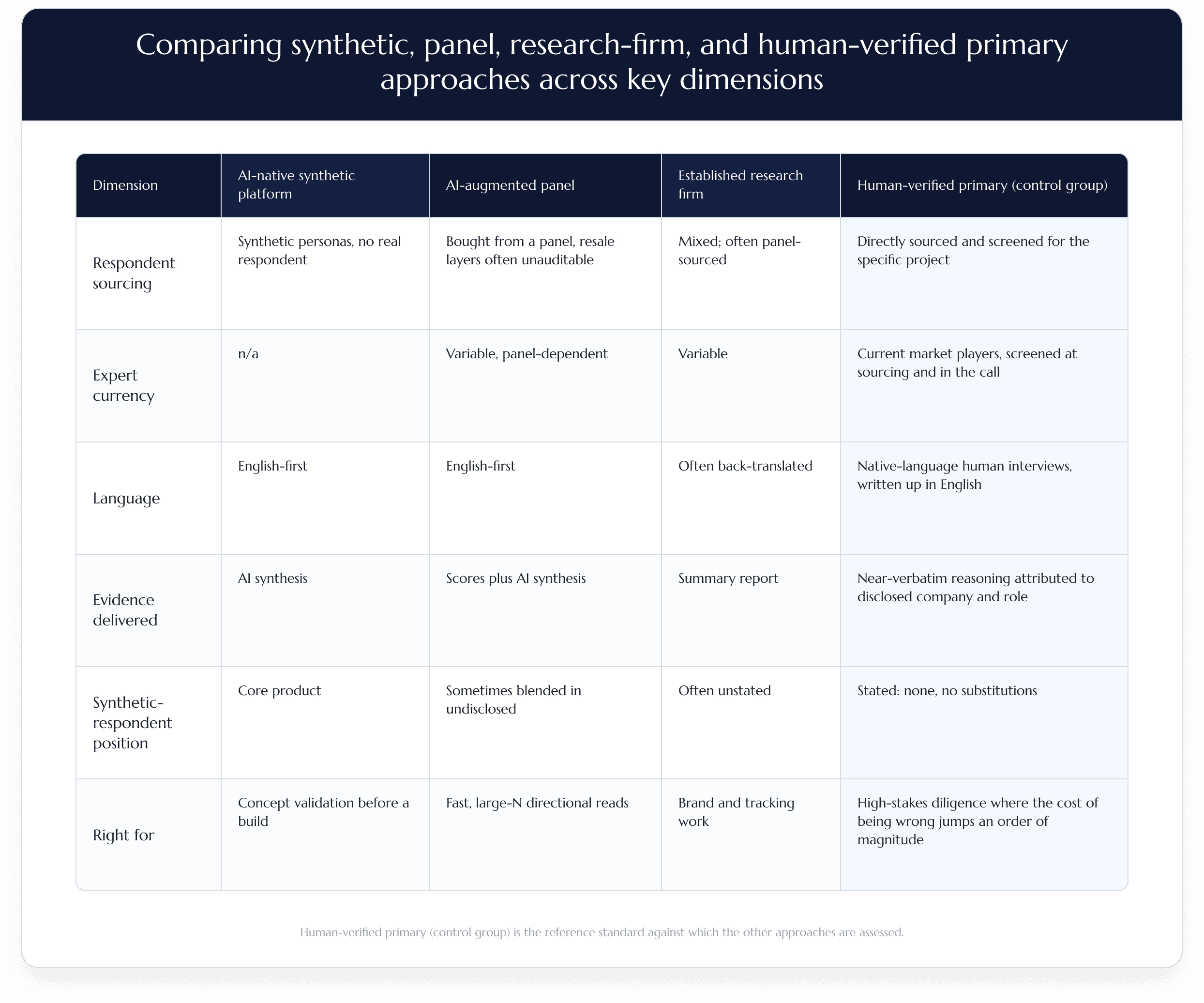
The table is not an argument that three of the four approaches are wrong. They are right for the work they are right for. The argument is narrower: when the cost of being wrong jumps an order of magnitude, the bottom row is the layer the rest of the stack gets measured against. That is the whole function of a control group. It does not replace the other inputs; it tells you which of them are describing the market and which are describing each other.
A worked example from our own files makes the mechanism concrete. A private equity firm was acquiring a B2B software provider serving a niche SME segment across Europe and North America, with a Big Four consultancy running the commercial due diligence. We were brought in to lead the primary research on a compressed timeline, and completed over 140 native-language interviews across Germany, France, and the USA in eight working days, with interim findings aligned every 24 hours (Bell & Holmes, Commercial Due Diligence case study). The syndicated and desk inputs framed the target as a stable incumbent. The interviews held that up in one respect — customers were sticky despite weak UX, because the product was wired into critical workflows — and broke it in another: strong unmet demand for a compliance module the target had not monetized, which moved the growth projection the deal team was underwriting. The number on the slide was not wrong so much as incomplete, and only the interviews showed which part.
How the market is already moving toward verification
Verification is moving from a marketing claim to an operational requirement, and the shift is arriving from several directions at once — not as a Bell & Holmes thesis landing on the market, but as the market converging on it independently.
MIT Sloan Management Review's 2026 Responsible AI panel put the principle plainly. As IAG's chief AI scientist Ben Dias put it, "every AI solution needs an accountable human who is responsible for ensuring that the system's outputs are properly understood and verified" (MIT Sloan Management Review, "Beyond Verification — What Responsible AI Really Demands of Human Experts," 2026). Penn State's guidance for generative AI in research is the institutional version of the same position: it places primary responsibility for verifying all AI-generated content, data, and references on the human researcher (Penn State Office for Research Protections, "Generative AI in Research"). When a Tier-1 research institution has codified the standard, the commercial research market is the one that lags.
What we hear in live engagements matches both. Deal teams are pressing harder on how respondents were sourced and screened, where two years ago the first questions were about turnaround and methodology. CDD leads at strategy firms are starting to write sourcing and native-language requirements into the scope of work itself, not the appendix. And in litigation-support and expert-witness work, disclosed, qualified sources and captured reasoning are not a positioning choice, they are evidentiary requirements, which is why this corner of the market reached the standard first.
We are not citing a quantitative trend here, because we do not have one we trust. We are describing a shift in what the buying conversation actually sounds like, in real engagements, in 2026.
The market is also splitting in two directions, and the split matters. On one side, AI-native qualitative platforms now sell synthetic personas, AI-moderated conversations, and 30-minute outputs at sub-$100/month pricing. The honest versions tell their own customers, in writing, that synthetic personas are not a fit for high-stakes decisions or anything that needs real-participant validation. Concept validation before a build: appropriate. A diligence sign-off on a major acquisition: not appropriate. Both can be true at once. The control-group thesis is not an argument against synthetic respondents existing. It is an argument that the moment the cost of being wrong jumps an order of magnitude, the stack needs a layer underneath the synthesis that the buyer can independently verify.
On the other side, established firms are leaning into trust-and-human-oversight rhetoric without committing to verifiable operational standards. "We use technology to enhance quality, not replace judgment" is a real position. It is also a sentence that can be true on the day of the pitch and silent on the day of the deliverable. The control-group test is what makes the rhetoric checkable: direct sourcing, current screened experts, native-language human interviews that capture the respondent's own words, a stated position on synthetic. A firm that lands on all four is describing an artifact. A firm that lands on none is describing a brand.

The honest objection
Human-verified primary research costs more per interview than an AI-augmented panel run, and it will not match the 30-minute turnaround of a synthetic simulation. That is true, and we are not going to pretend otherwise. But against the assumption that real interviews are slow, the gap is smaller than buyers expect: a directly sourced, native-language programme can deliver first interviews within 48 hours, and the diligence programme above closed 140+ in eight working days. The reframe on cost is simpler still. The cost of being wrong in commercial due diligence is not the research line item. It is the deal. A control group is the layer that tells you whether the rest of the stack is reading the market or reading itself, and it pays for itself the first time it catches an incomplete number before that number reaches the investment committee. The question is whether you want to know.
The next 24 months
The market is heading toward a stack where AI-augmented research is the default and human-verified primary research is the layer that makes the default interpretable. Within 24 months every defensible research programme will have a control group inside it, and the firms that can credibly produce one (directly sourced current experts, native-language human interviews, disclosed provenance, no synthetic substitutions) will be the ones getting the brief on the work that actually has to be right.
We are built for that role. If your next deal needs a layer underneath the AI synthesis, scope a control-group programme with us: directly sourced and screened respondents, native-language interviews, near-verbatim write-ups with disclosed company and role, no synthetic substitutions. The conversation starts with the deal, not the methodology deck.