01/07/2026
What Is Secondary Market Research — and How Fake Reports Reach Your Deal Deck
When a consulting firm cites a market size from Grand View Research and an LLM returns the same figure, both feel like independent sources. They aren't.
In 2018, Christoph Nichau, Managing Director at valantic Private Equity Practice, bought a 150-page market report for a due diligence project. It cost around $4,000. He has since described what was inside it: numbers that appeared out of thin air, packaged to look like research, with no survey, no interviews, and no methodology he could trace. The report read like authority, and underneath it was assumption with a price tag.
That is the subject of this article. A large share of what passes for secondary market research is packaged assumption wearing the costume of research, and once it enters a deck the costume is all anyone sees.
This is the second piece in our series on where bad market data comes from. The first, on human-verified primary research as the control group for AI data, was about how to verify a number once you have it. This one is about where the number was born.
What is secondary market research?
Secondary market research is data compiled from existing sources rather than collected directly for the project in front of you. You did not run the survey or conduct the interviews. Someone else did, or claimed to, and you are reading their output. That is the whole definition, and most of it is legitimate.
Secondary data splits into two groups, and the distinction matters more than most explainers admit. Internal secondary data is what your own organization already holds: prior studies, CRM records, sales figures, past deal files. It is the most traceable secondary data there is, because you know exactly where it came from. External secondary data is everything published by someone else, and that is where the trouble starts.
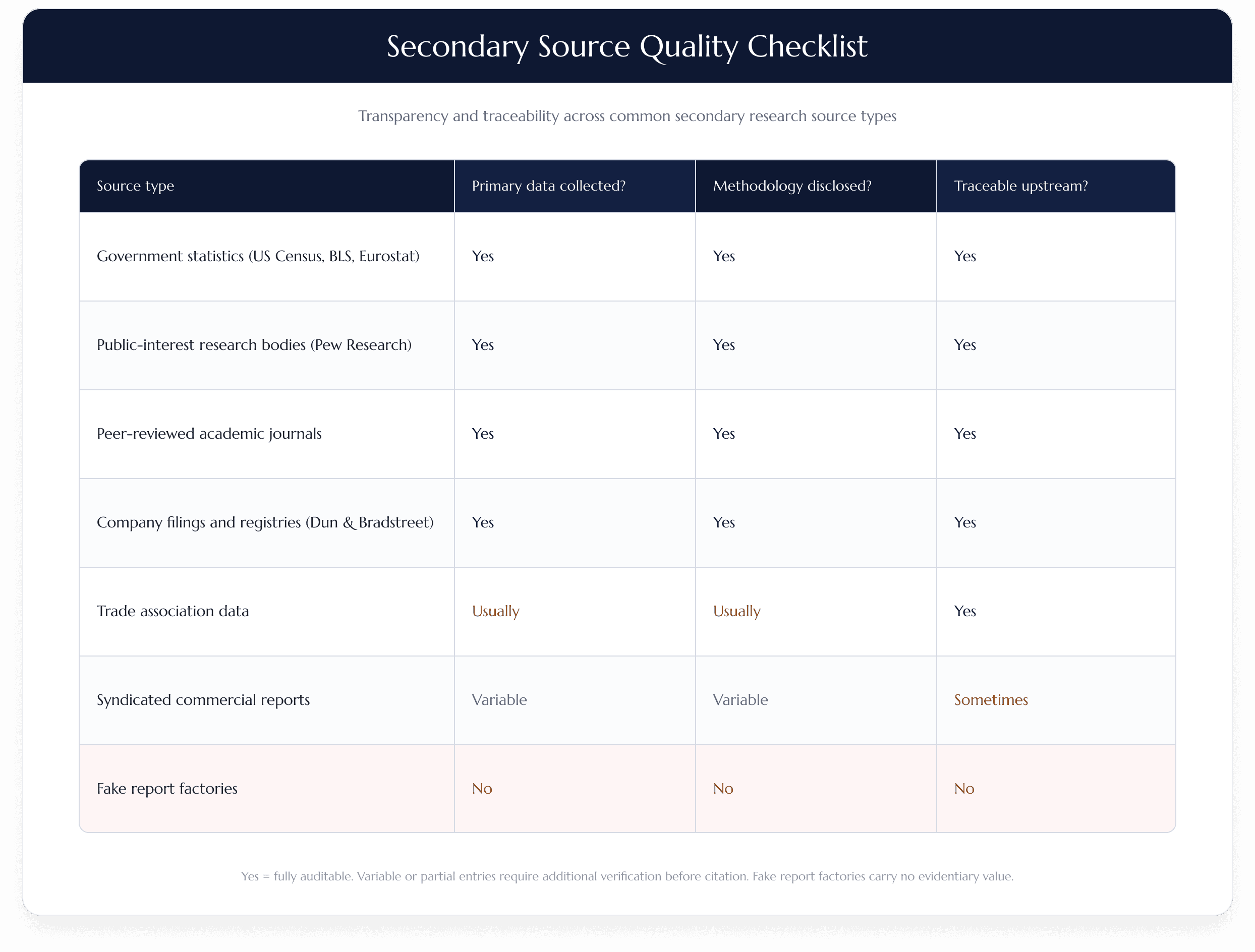
The trustworthy external sources are easy to name: government statistics from the BLS, Eurostat, or a national census; trade association data; peer-reviewed academic journals; company filings and annual reports. Each has a visible primary source and, usually, a market research methodology section you can read.
Then there is the problem category: syndicated commercial reports, the $4,000 PDF market. Some of these publishers do real fieldwork and disclose it. Many do not. What separates the two has nothing to do with price or page count, and everything to do with whether you can follow the number back to something that was actually measured.
What is the difference between primary and secondary market research?
Primary market research is data you commission and collect yourself: interviews, surveys, observation, run for the question in front of you. Secondary market research is data someone else already collected, which you are reading second-hand. The practical difference for a deal team is ownership of the chain. With primary research, you know who was asked, when, and how, because you set it up. With secondary research, you inherit someone else's method, or their lack of one.
The distinction is usually taught as a cost-and-speed trade-off: secondary is faster and cheaper to start, primary is slower and more expensive. That is true, and it buries the part that matters under deal pressure. Secondary data is only as trustworthy as the provenance behind it, and the provenance is exactly what most external secondary sources do not show. Primary research is the one category where you are the source, so the chain cannot dead-end on someone who will not show their method. That is the difference that survives deal pressure, long after the cost-and-speed comparison stops mattering.
How do fake report factories work?
A fake report factory produces market sizing without producing market data. This is fake market research in its purest form: no surveys, no interviews, no named methodology. The numbers are derived from other reports, which were derived from other reports, until the original measurement either never existed or can no longer be found. The output gets an executive summary, a set of charts, a brand, and a four-figure price.
The scale of this is documented. In a series of LinkedIn posts in spring 2026, Christoph Nichau profiled 153 of these publishers and found that 93.5% trace back to India, half of them to the single city of Pune. One publisher he examined, lists two employees on LinkedIn yet claims to have published more than 5,000 reports in a year, against roughly 3,500 a year from Gartner and its 17,000 staff. The business model he describes is built for search, not research: an SEO-optimised landing page ranks for "[category] market size," shows a headline number, and sells the full PDF for a few thousand dollars, with the report itself produced on demand only after someone buys it.
The incentive underneath is the part worth sitting with. The system rewards buying a number over admitting you do not have one. A deal team needs a market size by Thursday, and nobody on the call asks where the figure came from, because the figure arriving on time is what the meeting needs. A real sizing study means recruiting respondents, running interviews, and defending a method, which costs weeks and money. A fabricated report costs a writer an afternoon with a chart template, at the same price to the buyer and no way to tell the two apart from the cover.
If you have ever signed off on a TAM — total addressable market — you could not personally trace, you already understand the demand side from the inside.

What separates legitimate secondary research from a fabricated report?
The line between a real syndicated report and a fabricated one comes down to disclosure. A legitimate publisher tells you how the number was produced: who was surveyed, how many, when, in which markets, and what was estimated rather than measured. A fake report factory skips that section, or fills it with boilerplate. Christoph Nichau found that the methodology pages of these reports are often identical across publishers, sometimes word for word, with no primary source, no disclosed survey, and no government dataset behind the figure.
That reframes the buyer's job. You are not trying to tell a $4,000 report from a free one, or a long one from a short one. You are reading the market research methodology section and judging whether it describes real fieldwork. A report that explains its limits, including where it relied on desk research rather than fieldwork, is doing the thing a fabricated report cannot. When the methodology page is missing, vague, or replaced with a logo wall of "trusted by" brands, you are holding a number with no parents.
How does fabricated data get into AI outputs?
The fabricated number used to stay in the PDF. Now it propagates. The chain runs in one direction: a report gets published, Google indexes it, a reputable consulting deck cites it, the deck and the report get scraped into LLM training data, and an AI model later returns the figure as a confident, sourceless answer. By the last step, the original PDF is invisible. The number simply sounds true.
Nichau's analysis put numbers on the spread. Across the public output of the ten largest consulting firms — McKinsey, BCG, Bain, PwC, Deloitte, EY, KPMG, Accenture, Roland Berger, and Oliver Wyman — he documented 771 references to watchlist publishers, with one source cited by all ten firms. The problem does not stop at consulting decks. In a separate analysis of 9,324 annual reports from 189 major corporations, he found that 38% cited at least one of these publishers, often in formal reference sections rather than as passing mentions. An annual report is audited, board-approved, and filed with regulators, yet the market-sizing citation inside it can trace to a publisher with no disclosed method.
These are load-bearing citations inside the documents that carry the most institutional weight, not fringe sources buried in a footnote.
Why does AI make fabricated market data harder to catch?
An AI model cannot tell that a source was fabricated. It can only tell that the source was cited often, and citation frequency is not factual reliability. Once a number from one of these publishers is indexed widely enough, it gets scraped into training data and an AI model later returns it as a confident answer, with the original PDF nowhere in sight.
Christoph Nichau tested how deep this goes. Across 92 markets and three major AI models, he reported that one model produced $14.6 trillion in market-size claims with none of it traceable to an audited filing, government statistic, or any verifiable public source. Asked the same market-size question, three models diverged by an average of 67%, and in the worst case by more than 700%, for the same market and the same year. The fabricated figures are not a fringe error the models occasionally make; they are baked into what the models learned.
Picture the loop in a single project. A deal team runs a desk-research briefing through an LLM and gets a clean market size. The consulting firm advising the same deal runs a different LLM query and gets a figure within a point or two. Two independent tools, two independent queries, one number that agrees with itself, which feels like confirmation. In reality it can be the same fabricated figure surfacing twice, because both models learned it from the same indexed source. On an M&A deal, that is how both sides end up anchoring a valuation on one unverified number without realizing they share it. In a thin-data niche, that is not a rounding error. It is the valuation.
How do you check market data provenance?
Data provenance is the property that fabricated reports cannot fake: a clear path from the figure on your slide back to something that was measured. It is the standard a court applies to evidence, and an auditor applies to a number, and it is the one most market sizing quietly skips. Three questions catch most of the bad inputs.
- First, what was the primary source? A survey, a set of interviews, a government dataset, a body of filings — or nothing you can name. If the answer is "a market report," that is not a source. That is another slide.
- Second, can you follow the citation chain upstream? Good data survives the walk back. If the trail dead-ends at a commercial publisher with no methodology section, treat the figure as unverified.
- Third, was the number independently derived, or did one origin spread across many sources? This is the trap our piece on the AI data control group described from the other side. Five sources agreeing means nothing if all five read the same upstream PDF. The fix is triangulation: build a bottom-up estimate from inputs you can verify, then test it against the top-down syndicated figure.
When is primary research the only reliable source?
Secondary research fails hardest exactly where buyers lean on it most: niche markets, emerging geographies, pre-revenue sectors, and segments with no government reporting. There is no census for a specialist medtech category in three Central European markets. When the public data does not exist, a fake report factory is the most tempting place to look, and the most dangerous.
These are the cases where primary research stops being the slower option and becomes the only one with a traceable source. Not because primary data is virtuous, but because it is the only data with a person behind it you can call back. Secondary research still has its place. Government data and verified filings belong in every sizing model. The argument is narrower: when the number has to be right and the public sources cannot prove themselves, you have to go and collect it.
The threshold is worth making concrete. Commission primary research when three conditions hold at once: the figure is load-bearing for the thesis, the available secondary source has no methodology section you can inspect, and there is no government or regulatory dataset covering the segment. Hit all three and you are no longer choosing between cheap and expensive. You are choosing between a number you can defend in an investment committee and one you are hoping nobody asks about. Miss any one of the three and secondary will usually hold.
What does traceable primary research look like in practice?
Traceable primary research means every figure in the deliverable maps back to a named respondent, identified by role and company, whose identity the buyer can verify rather than take on trust. That is the work Bell & Holmes is built for. On one recent commercial due diligence for a global technology consultancy, the team ran 23 interviews with C-level decision-makers across six countries — Italy, the Netherlands, France, the UK, the US, and Canada — inside five working days, sourced directly rather than bought from a panel.
We covered the sourcing mechanics in our piece on cold calling in private equity due diligence and the compressed-timeline version in a Big 4 commercial due diligence case. Direct sourcing buys one thing above all: provenance you can hand to an investment committee, with a chain that does not dead-end at a publisher who will not show the method.

Deal teams have used these reports. Consulting firms have used them. So have we — every research firm has built a sizing model off a syndicated figure at some point. The reports are not going away, and not all of them are bad.
What has changed is the AI layer sitting on top of them. As Christoph Nichau put it in one of his posts, strategy built on fabricated market data is expensive guesswork dressed up in footnotes. The question for your own research stack is no longer whether secondary data is clean. It is whether the AI tools in front of it are amplifying the bad inputs or surfacing them.
If your next project needs market data with a traceable source, scope it with us. We source directly, interview in-market, and show the work behind the number.